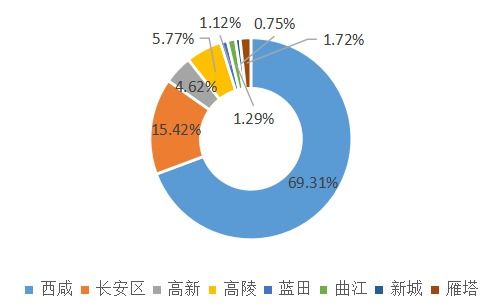
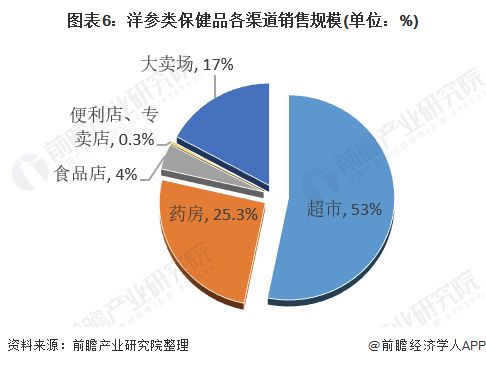
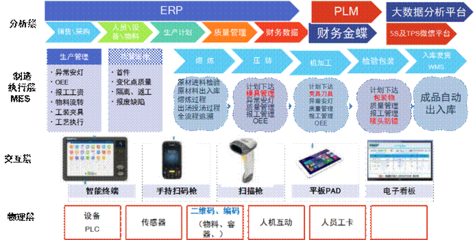
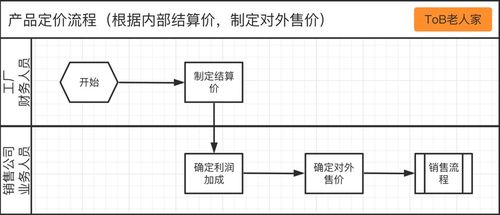
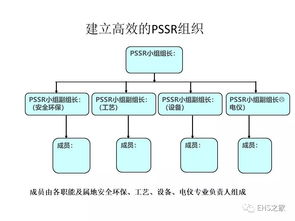
隨著數字化營銷的蓬勃發展,越來越多的銷售團隊開始利用數據分析工具優化營銷策略,而業務營銷文本詞云作為一種直觀的可視化工具,正逐漸成為提升銷售業務效率的重要助手。通過將銷售話術、客戶反饋和營銷內容中的高頻詞匯以圖形化形式展示,詞云不僅能幫助銷售團隊快速識別核心信息,還能為業務決策提供有力支持。
在銷售業務中,業務營銷文本詞云的應用主要體現在以下幾個方面。它能夠幫助團隊分析客戶需求。通過收集客戶咨詢記錄、產品評論或市場調研文本,生成詞云后,可以迅速發現客戶關注的焦點問題,如價格、性能或服務等關鍵詞,從而指導銷售策略的調整。詞云可用于優化營銷內容。銷售團隊可以將廣告文案、宣傳冊或社交媒體帖子的文本輸入,分析高頻詞匯是否與品牌核心價值一致,確保營銷信息傳遞的準確性與吸引力。在內部培訓中,詞云還能提煉出優秀銷售話術的關鍵元素,幫助新員工快速掌握溝通技巧,提升整體銷售業績。
生成業務營銷文本詞云通常依賴于專業工具或軟件,如Python的WordCloud庫、在線詞云生成器等。操作流程包括數據收集、文本預處理、詞頻統計和可視化設置。例如,銷售團隊可以整合多個渠道的營銷數據,過濾掉無關詞匯(如“的”、“是”等停用詞),然后根據詞頻大小生成詞云圖。值得注意的是,詞云的顏色、字體和布局可以自定義,以增強視覺效果,便于團隊在會議或報告中快速分享洞察。
盡管業務營銷文本詞云具有諸多優勢,但也存在一些局限性。它主要展示詞匯頻率,無法體現上下文關系或情感傾向,因此需要結合其他分析工具,如情感分析或主題建模,以獲得更全面的洞察。同時,數據質量直接影響詞云的準確性,如果營銷文本中存在大量噪音或不相關詞匯,可能會誤導分析結果。
隨著人工智能和自然語言處理技術的進步,業務營銷文本詞云有望與智能推薦系統結合,自動生成優化建議,進一步提升銷售業務的精準度。對于銷售團隊而言,善用詞云這一工具,不僅能節省時間,還能在競爭激烈的市場中保持領先優勢。業務營銷文本詞云作為銷售業務中的輔助利器,值得廣泛推廣和應用。